SBERT erklärt: Wie Google mit S-CTS KI-Spam im Web erkennen will
25.06.2026 um 10:15 Uhr, von Anne
Google geht verstärkt gegen KI-generierten Massencontent vor. Mit dem neuen System S-CTS und dem Sprachmodell SBERT setzt die Suchmaschine künftig auf semantische Analysen statt einfacher Wortvergleiche. Doch wie funktioniert die Technologie eigentlich und welche Auswirkungen hat sie auf SEO und den Einsatz von KI-Content?
- SBERT erklärt: Wie Google mit S-CTS KI-Spam im Web erkennen will
- Warum Google neue Methoden wie SBERT gegen KI-Spam benötigt
- Warum klassische Spam-Erkennung heute nicht mehr funktioniert
- Was ist SBERT?
- Wie SBERT technisch funktioniert
- Was ist S-CTS?
- Warum Google Verhalten und Inhalte kombiniert
- Warum SBERT gerade für KI-Spam besonders geeignet ist
- Wo die Grenzen von SBERT liegen
- Was bedeutet das für SEO?
- Meine Einschätzung
- Mein Fazit
Die Menge an KI-generierten Inhalten im Internet wächst rasant. Moderne Sprachmodelle können innerhalb weniger Minuten tausende Texte erzeugen, leicht umformulieren und über unterschiedlichste Websites oder Accounts veröffentlichen. Dieses Phänomen wird häufig als AI Slop bezeichnet und stellt Suchmaschinen zunehmend vor große Herausforderungen.
Für Google bedeutet das ein ernstes Problem. Die Suchmaschine verfolgt das Ziel, möglichst hilfreiche, originelle und vertrauenswürdige Inhalte bereitzustellen. Gleichzeitig wird es immer einfacher, mit generativer KI riesige Mengen nahezu identischer Inhalte zu produzieren und automatisiert zu veröffentlichen. Klassische Spam-Filter stoßen dabei zunehmend an ihre Grenzen.
Aus diesem Grund hat Google mit S-CTS (Scalable Cluster Termination System) einen neuen Ansatz vorgestellt, der auf SBERT (Sentence-BERT) basiert. Das Ziel besteht darin, KI-generierten Massencontent nicht anhand identischer Wörter zu erkennen, sondern anhand seiner tatsächlichen Bedeutung. Das ist ein fundamentaler Unterschied und zeigt gleichzeitig, wohin sich Googles Qualitätsbewertung künftig entwickelt.
Warum Google neue Methoden wie SBERT gegen KI-Spam benötigt
Mit jeder neuen Generation großer Sprachmodelle steigt die Qualität automatisch erzeugter Inhalte. Moderne KI-Systeme schreiben heute flüssig, grammatikalisch korrekt und variieren ihre Formulierungen so stark, dass viele Texte auf den ersten Blick einzigartig wirken. Genau dieses Prinzip nutzen Spam-Netzwerke gezielt aus. Häufig wird zunächst ein einziges Grundskript erstellt. Anschließend erzeugt eine KI daraus hunderte oder sogar tausende Varianten, bei denen Wörter ausgetauscht, Satzstrukturen verändert oder Absätze leicht umgeschrieben werden. Für klassische Prüfverfahren sehen diese Texte unterschiedlich aus, obwohl sie inhaltlich nahezu dieselbe Aussage transportieren.
Für Google entsteht dadurch ein enormes Problem. Wenn sich Spam nur noch über die Bedeutung eines Textes erkennen lässt und nicht mehr über identische Wörter, reichen herkömmliche Verfahren nicht länger aus. Genau hier setzt Googles neuer Ansatz an.
Warum klassische Spam-Erkennung heute nicht mehr funktioniert
Lange Zeit basierte Spam-Erkennung auf vergleichsweise einfachen Verfahren. Texte wurden anhand identischer Wörter, Zeichenfolgen oder sogenannter Hashwerte miteinander verglichen. Waren zwei Inhalte nahezu identisch, ließ sich Spam relativ zuverlässig erkennen. Mit generativer KI hat sich diese Situation jedoch grundlegend verändert.
Bereits kleine sprachliche Anpassungen reichen heute aus, damit zwei Texte technisch vollkommen unterschiedlich aussehen. Inhaltlich bleiben sie jedoch nahezu identisch. Ein einfacher Wortvergleich erkennt diese Zusammenhänge nicht mehr. Google musste deshalb einen neuen Weg finden, Inhalte nicht nach ihrer Formulierung, sondern nach ihrer tatsächlichen Aussage zu bewerten.
Was ist SBERT?
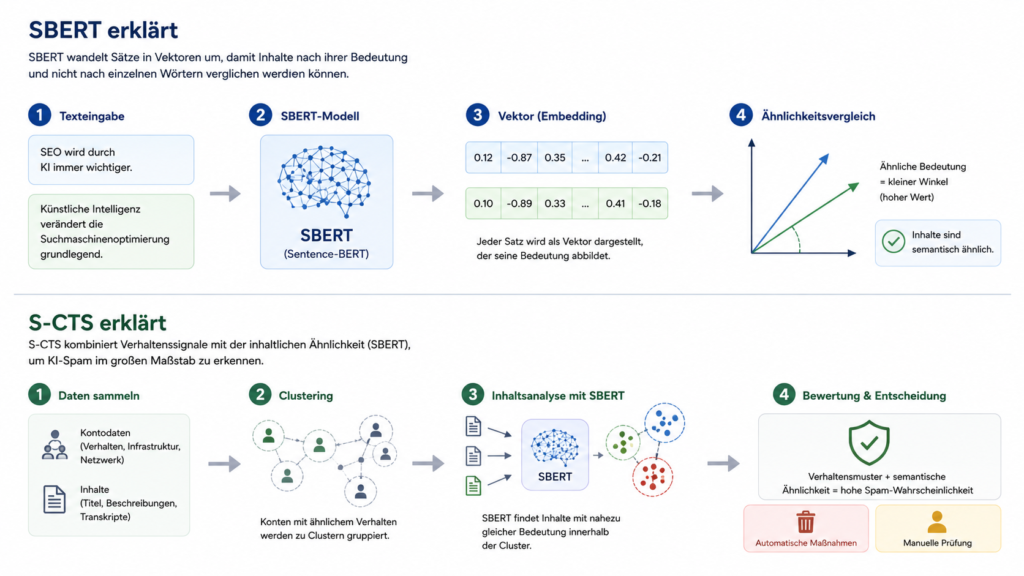
Die Grundlage des neuen Systems bildet SBERT, kurz für Sentence-BERT. SBERT ist eine Weiterentwicklung des bekannten Sprachmodells BERT und wurde entwickelt, um ganze Sätze oder Texte hinsichtlich ihrer Bedeutung miteinander vergleichen zu können. Während klassische Verfahren hauptsächlich Wörter vergleichen, versucht SBERT den eigentlichen Sinn eines Textes mathematisch abzubilden. Dafür wird jeder Satz in einen sogenannten Embedding-Vektor umgewandelt. Vereinfacht gesagt handelt es sich dabei um eine lange Zahlenfolge, die die semantische Bedeutung eines Satzes beschreibt. Zwei Sätze mit nahezu identischem Inhalt liegen im mathematischen Raum dadurch sehr nah beieinander, selbst wenn sie kaum dieselben Wörter verwenden.
Ein einfaches Beispiel verdeutlicht dieses Prinzip:
Die Aussagen „Die besten Laufschuhe für Anfänger im Jahr 2026“ und „Welche Laufschuhe eignen sich 2026 für Einsteiger?“ verwenden unterschiedliche Wörter und einen anderen Satzbau. Inhaltlich verfolgen beide Texte jedoch dieselbe Aussage. Genau diese semantische Nähe erkennt SBERT. .
Das Modell bewertet also nicht den Wortlaut eines Textes, sondern seine Bedeutung.
Wie SBERT technisch funktioniert
Technisch baut SBERT auf dem bekannten Transformer-Modell BERT auf, verändert allerdings den eigentlichen Verarbeitungsprozess erheblich. Während BERT normalerweise immer zwei Texte gleichzeitig analysieren muss, verarbeitet SBERT jeden Satz zunächst separat. Jeder Satz wird dabei nur ein einziges Mal durch das Modell geschickt und anschließend als fester Embedding-Vektor gespeichert. Dadurch entsteht ein enormer Geschwindigkeitsvorteil. Statt Millionen einzelne Satzkombinationen erneut berechnen zu müssen, vergleicht das System anschließend lediglich noch die entstandenen Vektoren miteinander. Das spart enorme Rechenleistung und macht SBERT auch bei Millionen Dokumenten praktikabel.
Für den eigentlichen Vergleich nutzt das Verfahren die sogenannte Kosinus-Ähnlichkeit. Dabei wird mathematisch berechnet, wie ähnlich sich zwei Vektoren sind. Je näher der Wert an 1 liegt, desto ähnlicher ist die Bedeutung der beiden Texte. Liegt der Wert dagegen deutlich niedriger, unterscheiden sich die Inhalte stärker voneinander. Das Entscheidende dabei ist: SBERT erkennt keine identischen Wörter. Das Modell erkennt semantische Nähe.
Was ist S-CTS?
SBERT allein erkennt allerdings noch keinen Spam. Genau deshalb entwickelte Google zusätzlich S-CTS, das Scalable Cluster Termination System. S-CTS kombiniert verschiedene Informationsquellen miteinander und bewertet nicht nur Texte selbst, sondern auch das Verhalten der dahinterstehenden Accounts. Dadurch entsteht ein deutlich robusteres System als eine reine Inhaltsanalyse. Zunächst untersucht Google sogenannte Generation Clusters. Dabei analysiert das Unternehmen interne Signale, technische Gemeinsamkeiten, Infrastrukturen und auffällige Verhaltensmuster. Ziel ist es, Gruppen von Accounts zu identifizieren, die wahrscheinlich gemeinsam automatisierte Inhalte veröffentlichen. Erst danach kommt SBERT zum Einsatz.
Das Modell analysiert die eigentlichen Inhalte und prüft, ob sich über verschiedene Accounts hinweg auffällig viele Texte mit nahezu identischer Bedeutung finden lassen. Erst wenn beide Signale zusammenpassen, also koordiniertes Verhalten und semantisch ähnliche Inhalte, steigt die Wahrscheinlichkeit, dass es sich tatsächlich um automatisierten KI-Spam handelt. Genau diese Kombination macht S-CTS so interessant.
Warum Google Verhalten und Inhalte kombiniert
Ein besonders spannender Aspekt von S-CTS besteht darin, dass Google sich bewusst gegen eine reine Textanalyse entschieden hat. Denn ähnliche Inhalte sind nicht automatisch Spam. Zwei seriöse Nachrichtenportale berichten über dasselbe Ereignis häufig ebenfalls sehr ähnlich. Auch Produktbeschreibungen, Pressemitteilungen oder technische Dokumentationen können sich inhaltlich stark überschneiden, ohne gegen irgendwelche Richtlinien zu verstoßen. Würde Google ausschließlich SBERT verwenden, könnten hochwertige Inhalte fälschlicherweise als Spam eingestuft werden.
Deshalb kombiniert S-CTS die semantische Analyse mit zahlreichen weiteren Signalen. Dazu gehören beispielsweise ungewöhnliche Upload-Muster, technische Gemeinsamkeiten zwischen Accounts oder koordinierte Veröffentlichungen innerhalb kurzer Zeiträume. Erst das Zusammenspiel dieser Informationen ermöglicht eine deutlich zuverlässigere Bewertung.
Warum SBERT gerade für KI-Spam besonders geeignet ist
Der große Vorteil von SBERT besteht darin, dass das Modell nicht versucht zu erkennen, welche KI einen Text geschrieben hat. Viele klassische KI-Detektoren suchen nach charakteristischen Schreibmustern einzelner Sprachmodelle. Dieses Verfahren wird allerdings schnell unzuverlässig, sobald neue Modelle erscheinen oder bestehende Systeme verbessert werden. SBERT verfolgt einen anderen Ansatz.
Das Modell interessiert sich ausschließlich für den fertigen Inhalt. Ob ein Text von GPT, Gemini, Claude oder einem zukünftigen Sprachmodell stammt, spielt dabei zunächst keine Rolle. Entscheidend ist lediglich, welche Bedeutung der Text transportiert. Dadurch altert das Verfahren deutlich langsamer als viele klassische KI-Detektoren.
Wo die Grenzen von SBERT liegen
Trotz seiner Stärken besitzt auch SBERT klare Grenzen. Das Modell erkennt lediglich, ob Inhalte semantisch ähnlich sind. Es entscheidet jedoch nicht, ob ein einzelner Text hochwertig ist oder tatsächlich gegen Googles Richtlinien verstößt. Genau darin liegt auch eine der größten Herausforderungen. Sollten zukünftige Sprachmodelle Inhalte deutlich abwechslungsreicher formulieren oder bewusst zusätzliche Themen und Informationen einbauen, könnten sich die semantischen Ähnlichkeiten verringern. Dadurch würde auch die Erkennung schwieriger.
Google betrachtet SBERT deshalb ausdrücklich nicht als alleinige Lösung. Vielmehr soll das Modell künftig gemeinsam mit weiteren Verfahren arbeiten. Dazu gehören beispielsweise kryptografische Herkunftsnachweise wie C2PA, digitale Wasserzeichen wie SynthID sowie zahlreiche weitere Qualitätssignale. SBERT bleibt damit ein wichtiger Baustein innerhalb eines deutlich größeren Bewertungssystems.
Was bedeutet das für SEO?
Für seriöse Webseitenbetreiber ist die Vorstellung von S-CTS zunächst eine positive Entwicklung. Google macht damit deutlich, dass nicht KI-generierte Inhalte grundsätzlich problematisch sind. Im Mittelpunkt steht vielmehr automatisierter Massencontent ohne eigenen Mehrwert. Wer KI sinnvoll als Unterstützung nutzt, Inhalte redaktionell überprüft und originäre Informationen ergänzt, dürfte durch S-CTS kaum Nachteile erwarten müssen.
Problematisch werden dagegen Strategien, bei denen tausende nahezu identische Seiten automatisiert veröffentlicht werden und lediglich minimale sprachliche Unterschiede aufweisen. Genau solche Muster möchte Google künftig deutlich zuverlässiger erkennen. Das bestätigt erneut, dass moderne SEO längst nicht mehr auf Masse setzt, sondern auf Qualität, Originalität und semantische Relevanz.
Meine Einschätzung
Die Vorstellung von S-CTS zeigt sehr deutlich, wohin sich Googles Qualitätsbewertung entwickelt. Die Suchmaschine analysiert Inhalte zunehmend ganzheitlich. Statt einzelne Dokumente isoliert zu betrachten, bewertet Google immer stärker Zusammenhänge, semantische Muster und das Verhalten ganzer Netzwerke. Das passt perfekt zur Entwicklung moderner Suchsysteme. KI verändert nicht nur die Erstellung von Inhalten, sondern auch deren Bewertung.
Für SEO bedeutet das vor allem eines: Der Fokus verschiebt sich immer stärker auf echten Mehrwert. Nicht die Frage, ob ein Text mit KI erstellt wurde, entscheidet künftig über seine Qualität. Entscheidend ist vielmehr, ob Inhalte originell, hilfreich und eigenständig sind.
Mein Fazit
Mit SBERT und S-CTS verfolgt Google einen deutlich moderneren Ansatz zur Erkennung von KI-Spam. Anstatt lediglich identische Texte zu erkennen, analysiert das System deren tatsächliche Bedeutung und kombiniert diese Informationen mit Verhaltensmustern verdächtiger Accounts. Dadurch lassen sich automatisiert erzeugte Content-Netzwerke deutlich zuverlässiger identifizieren als mit klassischen Spam-Filtern.
Für SEO ist das ein wichtiges Signal. Google entwickelt seine Algorithmen zunehmend weg von einfachen Wortvergleichen hin zu einer semantischen Bewertung von Inhalten. Wer KI verantwortungsvoll einsetzt, originäre Inhalte erstellt und echten Mehrwert liefert, muss neue Verfahren wie S-CTS daher nicht als Bedrohung verstehen, sondern eher als Chance für qualitativ hochwertige Inhalte.