Googlebot gibt es nicht – was wirklich hinter Googles Crawling-Maschine steckt
17.03.2026 um 09:49 Uhr, von Anne
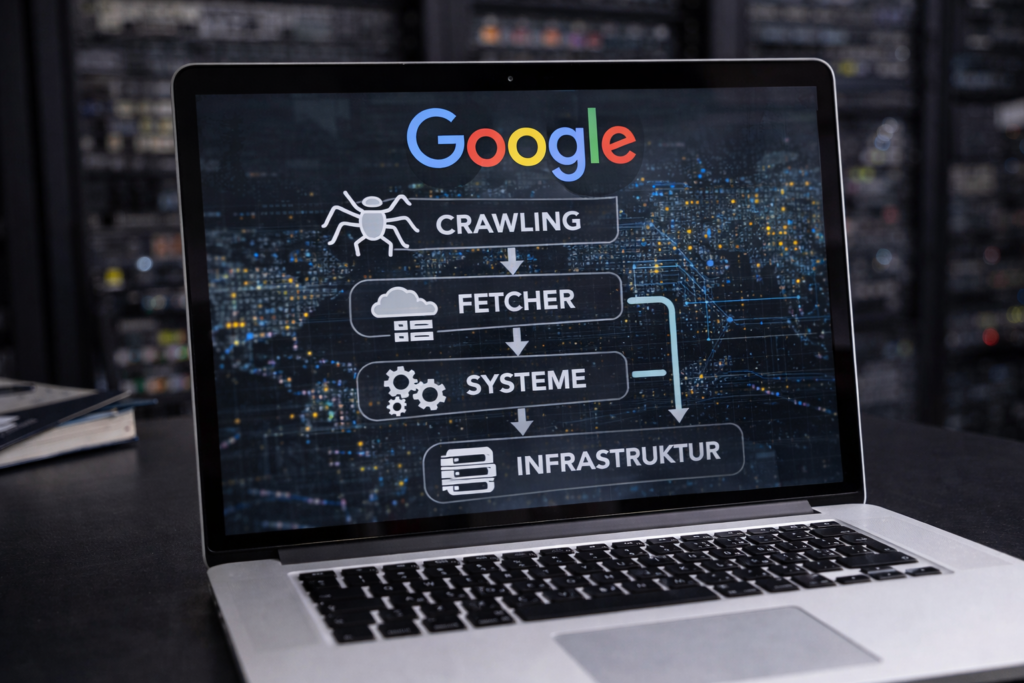
Viele SEOs stellen sich den Googlebot immer noch wie eine Art digitalen Staubsauger vor: ein Programm, das durchs Internet fährt und Inhalte einsammelt. Klingt praktisch. Ist aber falsch.
Denn: „Den Googlebot“ als einzelne Software gibt es so nicht. Dahinter steckt eine gigantische Infrastruktur, eher Cloud-System als Bot. Das wurde kürzlich auch im Podcast „Search Off The Record“ von Googles Search-Relations-Team erklärt.
Und ja: Das hat mehr mit Software-Architektur als mit SEO-Romantik zu tun.
Googlebot ist kein Bot sondern ein System
Im Podcast wird klar: „Googlebot“ ist vor allem ein Begriff für eine Zugriffsschicht auf Googles Crawling-Infrastruktur. Dahinter laufen zahlreiche Dienste, Systeme und Prozesse parallel. Statt eines Programms existiert also ein skalierbares System, das intern wie eine Art „Crawling-as-a-Service“ funktioniert. Verschiedene Google-Produkte nutzen diese Infrastruktur, um Inhalte aus dem Web abzurufen.
Für SEOs bedeutet das:
Crawling ist kein linearer Prozess. Es ist eine orchestrierte Cloud-Operation mit Priorisierung, Lastmanagement und massivem Parallelismus.
Crawling funktioniert wie ein Plattform-Service
Google beschreibt seine Infrastruktur im Grunde wie eine Plattform, die intern von Teams genutzt wird. Parameter wie URL, User-Agent oder Zeitlimits werden übergeben, der Rest passiert automatisiert im Backend. Das klingt weniger romantisch als ein einzelner Bot, ist aber deutlich realistischer. Denn bei Milliarden URLs braucht es keine „Crawler-Software“, sondern verteilte Systeme.
Oder anders gesagt:
Google crawlt nicht wie ein Besucher. Google crawlt wie ein Rechenzentrum.
Crawler vs. Fetcher: Googles zweistufiges System
Ein weiterer wichtiger Punkt aus dem Podcast: Google unterscheidet zwischen
- Crawlern, die kontinuierlich große Mengen an URLs verarbeiten
- Fetchern, die gezielt einzelne Inhalte abrufen
Fetcher können beispielsweise durch Nutzeraktionen ausgelöst werden. Crawler hingegen arbeiten automatisiert in großen Batch-Prozessen. Das erklärt auch, warum manche Seiten schneller gecrawlt werden als andere. Nicht jede URL landet automatisch im gleichen Workflow.
Warum das für SEO wichtiger ist als Rankings
Die wichtigste Erkenntnis ist banal, aber entscheidend:
Wenn Google Inhalte nicht crawlen kann, kann es sie auch nicht ranken.
Das bedeutet:
Technische SEO bleibt die Grundlage.
Saubere Architektur, stabile Server und eine funktionierende robots.txt sind weiterhin Pflicht.
Der Robots-Exclusion-Standard dient dabei als Hinweismechanismus für Crawler, auch wenn er kein absoluter Schutz vor Indexierung ist. Die große Infrastruktur im Hintergrund ändert nichts daran, dass fundamentale Zugänglichkeit weiterhin der erste Schritt jeder SEO-Strategie ist.
Googles Infrastruktur: gigantisch, aber pragmatisch
Google hat Crawling so aufgebaut, dass Websites möglichst nicht überlastet werden. Systeme reagieren auf Server-Errors, reduzieren die Geschwindigkeit und respektieren technische Signale. Das Ziel ist nicht, möglichst aggressiv zu crawlen, sondern effizient.
Denn selbst für Google gilt: Ein kaputter Server liefert keine guten Suchergebnisse.
Fazit: Der Mythos Googlebot ist vorbei
Der Googlebot ist kein einzelner Bot. Er ist ein Symbol für eine der größten technischen Infrastrukturen im Internet.
Für SEOs heißt das:
Weniger Bot-Mythen, mehr Systemverständnis.
Wer Crawling als Cloud-Prozess begreift, versteht auch besser, warum technische SEO, Performance und Architektur langfristig wichtiger sind als kurzfristige Ranking-Hacks.
Oder kurz gesagt:
Google crawlt nicht wie ein Bot. Google crawlt wie ein Betriebssystem.