Google Discover: Wie Google Inhalte auswählt und was Publisher daraus lernen können
25.02.2026 um 12:28 Uhr, von Anne

Für viele Websitebetreiber ist Google Discover gleichzeitig Traum und Frustration. Während manche Artikel innerhalb weniger Stunden enorme Reichweiten erreichen, bleiben andere Inhalte trotz guter Rankings in der klassischen Suche völlig unsichtbar. Lange war unklar, nach welchen Prinzipien Google entscheidet, welche Inhalte im Discover-Feed erscheinen. Neue Analysen liefern nun jedoch deutlich mehr Einblick in die Arbeitsweise des Systems und zeigen, dass Discover weit stärker strukturiert arbeitet, als viele bisher angenommen haben.
Dabei wird auch deutlich: Wer Discover verstehen möchte, muss sich von klassischen SEO-Denkweisen ein Stück weit verabschieden.
Google Discover ist keine Suche — sondern ein Empfehlungssystem
Der größte Denkfehler im Umgang mit Google Discover besteht darin, das System wie eine Suchmaschine zu behandeln. Während Google Search auf konkrete Suchanfragen reagiert, verfolgt Discover einen anderen Ansatz. Inhalte werden Nutzern angezeigt, ohne dass diese aktiv danach suchen.
Statt Keywords stehen Interessen im Mittelpunkt.
Google analysiert kontinuierlich, mit welchen Themen sich Nutzer beschäftigen, welche Inhalte sie lesen oder anklicken und welche Entwicklungen aktuell relevant sein könnten. Auf dieser Basis entsteht ein personalisierter Feed, der vor allem über die Google App, Android-Geräte oder mobile Chrome-Startseiten ausgespielt wird.
In gewisser Weise erinnert Discover deshalb stärker an moderne Social-Media-Feeds als an klassische organische Suche. Inhalte konkurrieren nicht nur um Rankings, sondern um Aufmerksamkeit.
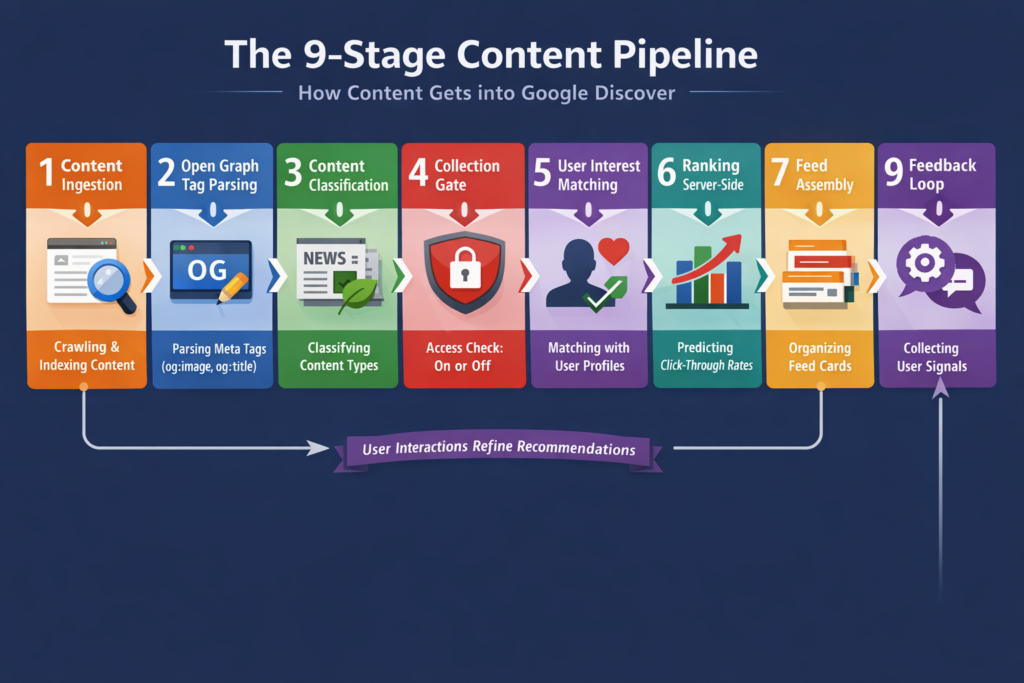
Neue Analysen zeigen eine klare Auswahlpipeline für Inhalte
Untersuchungen und technische Analysen aus der SEO-Branche deuten darauf hin, dass Inhalte in Google Discover mehrere Bewertungsstufen durchlaufen. Sowohl Auswertungen zeigen, dass Google offenbar eine mehrstufige Content-Pipeline nutzt, bevor Inhalte breit ausgespielt werden.
Das erklärt auch ein Phänomen, das viele Publisher kennen: Discover-Traffic erscheint häufig plötzlich und kann ebenso schnell wieder verschwinden. Reichweite entsteht nämlich nicht sofort, sondern erst nachdem Inhalte verschiedene Prüf- und Testphasen erfolgreich durchlaufen haben.
Die Content-Pipeline hinter Google Discover
Nach aktuellem Verständnis beginnt der Prozess ähnlich wie in der normalen Suche, entwickelt sich danach jedoch deutlich anders weiter.
Zunächst muss ein Inhalt natürlich von Google gecrawlt und indexiert werden. Technische Grundlagen bleiben also entscheidend. Seiten müssen erreichbar sein, mobil gut funktionieren und schnell laden. Ohne saubere technische Basis gelangt ein Artikel gar nicht erst in die nächste Bewertungsphase.
Anschließend folgt eine Qualitätsprüfung. Google bewertet hier unter anderem die Vertrauenswürdigkeit einer Website, die inhaltliche Substanz sowie das Verhältnis zwischen redaktionellem Inhalt und Werbung. Systeme wie Helpful Content oder E-E-A-T spielen dabei vermutlich eine wichtige Rolle. Danach versucht Google zu verstehen, worum es inhaltlich tatsächlich geht. Entitäten, Themenzusammenhänge und die generelle Expertise einer Website werden analysiert. Websites mit klar erkennbarem thematischen Schwerpunkt haben hier einen deutlichen Vorteil gegenüber sehr breit aufgestellten Projekten.
Erst danach beginnt der eigentliche Discover-Mechanismus.
Google gleicht Inhalte mit bestehenden Nutzerinteressen ab. Dabei spielen sogenannte Interest Graphs eine Rolle, also langfristig aufgebaute Interessenprofile einzelner Nutzergruppen. Gleichzeitig bewertet das System die Aktualität eines Inhalts. Besonders neue Entwicklungen, Branchennews oder Einordnungen aktueller Ereignisse scheinen bevorzugt behandelt zu werden.
Im nächsten Schritt versucht Google vorherzusagen, wie Nutzer auf einen Inhalt reagieren könnten. Klickwahrscheinlichkeit, potenzielle Interaktion oder Lesedauer werden algorithmisch eingeschätzt. Visuelle Elemente wie große Bilder oder klare Headlines gewinnen hier erheblich an Bedeutung.
Viele Inhalte werden anschließend zunächst nur testweise ausgespielt. Kleine Nutzergruppen fungieren gewissermaßen als Frühindikator. Erst wenn Engagement-Signale positiv ausfallen, skaliert Google die Reichweite deutlich. Genau an dieser Stelle entstehen die bekannten Traffic-Spitzen, die Discover so attraktiv, aber auch unberechenbar machen.
Das pCTR-Modell: Wie Google Klickwahrscheinlichkeit bewertet
Ein besonders spannender technischer Hinweis aus den Analysen betrifft das sogenannte pCTR-Modell (predicted click-through rate). Dabei handelt es sich um ein System, das vorhersagt, mit welcher Wahrscheinlichkeit Nutzer auf einen Inhalt klicken werden. Hinweise auf dessen Existenz finden sich unter anderem im Telemetrie-Ereignis PCTR_MODEL_TRIGGERED. Gleichzeitig zeigt sich jedoch eine wichtige Einschränkung: Dieses Event ist Teil einer allgemeinen Google-Telemetrie, die auch in völlig anderen Produkten verwendet wird. Das deutet stark darauf hin, dass die eigentliche Bewertung nicht im Discover-Client selbst stattfindet, sondern serverseitig innerhalb von Googles Ranking-Infrastruktur.
Was sich allerdings nachvollziehen lässt, sind die Signale, die vor einer Rankingentscheidung an Googles Server übermittelt werden. Dazu gehören unter anderem Titelinformationen, Bildqualität, Aktualitätssignale sowie historische Leistungsdaten wie Impressionen und Klickzahlen einzelner URLs. Auch Faktoren wie fehlgeschlagene Bildladevorgänge oder zeitliche Aktualität (freshness_delta_in_seconds) werden erfasst. Besonders interessant ist dabei, dass Titeltexte bereits strukturiert übertragen werden, bevor Discover Inhalte testweise ausspielt. Ob das pCTR-Modell diese Daten direkt verarbeitet, lässt sich zwar nicht nachweisen, sicher ist jedoch, dass sie Teil der Entscheidungsgrundlage sind, auf deren Basis Reichweite prognostiziert wird.
Open-Graph-Tags: Die Metadaten entscheiden über Sichtbarkeit im Feed
Neben Nutzersignalen spielen überraschend klassische technische Grundlagen weiterhin eine zentrale Rolle. Die Analyse zeigt, dass Google Discover clientseitig eine klar definierte Gruppe von Open-Graph-Tags ausliest und verarbeitet. Besonders entscheidend sind dabei og:image und og:title. Ohne ein geeignetes Bild kann häufig keine Discover-Karte erzeugt werden, wodurch Inhalte bereits vor der eigentlichen Bewertung aus dem Feed fallen. Gleichzeitig wird der Titel aus og:title extrahiert und zusammen mit weiteren Inhaltsmetadaten an Googles Server übertragen.
Darüber hinaus verarbeitet Discover unter anderem og:site_name zur Publisher-Zuordnung sowie og:locale, um Inhalte mit regionalen Nutzerinteressen abzugleichen. Interessant ist auch die interne Fallback-Logik: Fehlt ein primärer Open-Graph-Wert, versucht das System Ersatzquellen zu nutzen — etwa Twitter-Metadaten oder den klassischen HTML-Title. Bei Bildern reicht diese Fallback-Kette sogar über mehrere Ebenen, bevor Discover aufgibt. Für Publisher bedeutet das eine klare praktische Konsequenz: Sauber gepflegte Open-Graph-Daten erhöhen nicht nur die Darstellungskontrolle, sondern entscheiden häufig darüber, ob Inhalte überhaupt die Chance bekommen, im Discover-Feed getestet zu werden.
Welche Inhalte besonders gut im Discover-Feed funktionieren
Beobachtungen zahlreicher Publisher zeigen inzwischen klare Muster. Besonders erfolgreich sind Inhalte, die aktuelle Entwicklungen einordnen oder neue Informationen verständlich erklären.
Reine Evergreen-Ratgeber erscheinen deutlich seltener im Feed. Discover bevorzugt Inhalte mit Aktualitätsbezug oder klar erkennbarem Nachrichtenwert. Der entscheidende Unterschied liegt häufig darin, ob ein Artikel lediglich Wissen vermittelt oder hilft zu verstehen, warum ein Thema gerade relevant ist.
Anforderungen für Seitenbetreiber: Qualität allein reicht nicht
Auch wenn Google keine vollständige Liste an Rankingfaktoren veröffentlicht, lassen sich aus den Analysen einige klare Anforderungen ableiten.
- Discover ist stark visuell geprägt. Große, hochwertige Bilder erhöhen die Wahrscheinlichkeit, Aufmerksamkeit im Feed zu erzeugen. Kleine oder generische Stockbilder schneiden dagegen deutlich schlechter ab.
- Ebenso wichtig ist thematische Autorität. Websites, die regelmäßig über bestimmte Themen berichten, scheinen häufiger berücksichtigt zu werden als Seiten, die nur gelegentlich einzelne Trendthemen aufgreifen.
- Hinzu kommt die technische Perspektive. Da Discover überwiegend mobil genutzt wird, bleiben Ladezeiten und Nutzererfahrung entscheidend. Schlechte Performance kann bereits früh im Auswahlprozess zum Ausschluss führen.
- Auch Vertrauen spielt eine zunehmende Rolle. Transparente Autorenprofile, nachvollziehbare Expertise und eine klare redaktionelle Ausrichtung helfen Google dabei, Inhalte besser einzuordnen.
Warum Discover-Traffic oft wieder verschwindet
Viele Publisher erleben Discover zunächst als starken Wachstumstreiber, nur um wenige Wochen später deutliche Einbrüche zu sehen. Das liegt weniger an Abstrafungen als an der Funktionsweise des Systems selbst.
Nutzerinteressen verändern sich kontinuierlich. Themen verlieren an Dynamik, neue Trends entstehen und Engagement-Signale schwanken. Wenn Inhalte nicht mehr ausreichend Interaktion erzeugen, reduziert Google automatisch die Ausspielung. Discover belohnt daher langfristige Themenkompetenz stärker als kurzfristige Traffic-Optimierung.
Google Discover optimieren: Was tatsächlich funktioniert
Eine klassische SEO-Checkliste gibt es für Discover nicht. Dennoch zeigen sich klare Erfolgsprinzipien. Keyword-Optimierung allein reicht kaum aus. Ebenso wenig funktionieren große Mengen schnell produzierter Inhalte ohne klare redaktionelle Linie.
Deutlich erfolgreicher sind Publisher, die Themen strategisch aufbauen, Entwicklungen früh einordnen und Inhalte visuell attraktiv präsentieren. Besonders Analyseformate oder verständliche Erklärstücke scheinen gute Chancen zu haben, getestet und anschließend skaliert zu werden. Am Ende entscheidet weniger der einzelne Rankingfaktor als die Frage, ob Nutzer tatsächlich Interesse zeigen.
Fazit: Discover zeigt die Zukunft der Content-Distribution
Google Discover verändert die Art, wie Inhalte Reichweite erhalten. Nicht mehr allein Suchanfragen bestimmen Sichtbarkeit, sondern die Fähigkeit eines Inhalts, Interesse auszulösen und Nutzer zu binden.
Für Publisher bedeutet das eine klare Verschiebung: weg von rein keywordgetriebenem Content hin zu journalistischer Einordnung, Themenexpertise und echter Relevanz.
Oder etwas zugespitzt formuliert: Wer Discover verstehen möchte, sollte weniger wie ein klassischer SEO und ein wenig mehr wie eine Redaktion denken.
Häufige Fragen zu Google Discover
Quellen: sesuedwest.de, metehan.ai
Weitere Themen von WHAT ABOUT SEARCH

Studie: AI Overviews senken organische Klickrate in Deutschland dramatisch
Webseiten in 2026: Braucht man sie noch – oder übernimmt KI?

AI-Performance in den Bing Webmaster Tools: Endlich AI-Sichtbarkeit messbar

Google, KI-Optimierung und das Problem mit Empfehlungen von heute

Warum viele KMUs bei SEO noch zögern – und warum sie es sich nicht leisten können